
15 minute read
1. The Benefits of an Open (Edge) AI Accelerator Exchange
2. Innovations in Hardware and Software Are Expanding our Field
3. We Need to Work Jointly to Grow the Edge AI Market
4. Standardization to Ensure Adoption and Fast Growth
5. Explaining the VISION + AI pipeline
6. CPUs & XPUs Implementing an AI pipeline
7. The Challenges When “Outsourcing” Operations
8. Specifying Operations: Choosing the Right Level of Abstraction
9. The OAAX Specification
10. Operation Conversion Toolchains
11. XPU Operation Runtime
12. The ONNX Runtime
13. Opening up the Accelerator
14. The Nx Commitment
The Benefits of an Open (Edge) AI Accelerator Exchange
The Edge AI market has been growing steadily for a few years, but, in all honesty, it is still in its infancy. Certainly, we see some amazing applications of AI at the edge – think self-driving cars, advanced video security applications, and AI-driven automation in manufacturing. However, the true wave of edge AI adoption is yet to come.
Consider the subset of edge AI applications that we like to call “Video+AI”: AI applications consisting of a video camera enhanced by an AI model. Video+AI at the edge creates a virtually all-purpose sensor. This subset of the edge AI market is about to explode. Large-scale Video+AI applications already exist: in the security vertical Video+AI powers millions of cameras (we know because these applications are often built using the Nx Enterprise Video Platform / Nx Meta Developer Tools). However, the opportunities are much bigger: The cameras that are currently monitoring intruders at construction sites could also be used to monitor dangerous situations and alert workers timely. Or, the cameras currently used to catch burglars in a cafe could monitor which customers need attention, and which inventory items are almost out of stock. To be honest, the opportunities of Vision+AI are pretty much endless: any business process that can be improved by a trained and well-motivated human observing the scene can benefit from Vision+AI.
So, the future market opportunities seem endless. That said, conquering the market is easier said than done. One of the current inhibitors of market growth is the fact that it is still excessively hard to scale edge AI ideas from a first Proof of Concept (PoC) to a full-fledged solution. In particular, it is hard to bring together novel advances in software (model design, algorithms) and hardware (novel AI-specific hardware accelerators) efficiently. If we want to truly expand our market, we need to make it easier to deploy an edge AI application on the hardware that is most suitable for the application at hand. It is this problem that we address with the creation of the Open AI Accelerator Exchange.
Innovations in Hardware and Software Are Expanding Our Field
The edge AI market expansion is fueled by new innovations in both hardware and software. On the software side, we see new model architectures pop up rapidly. We have seen the emergence of generative AI, making it easy to train context-robust models with limited training data. We have seen ever more effective neural network architectures that are smaller than before, but still have a high accuracy. And, in recent years, we have seen an explosion of tools and frameworks to make curating training data and training AI models easier and easier: at this point in time highly accurate AI models can be trained by non-experts.
On the hardware side, we have seen an explosion of, what we will call throughout this white paper, accelerators (or XPUs). With this term, we will refer to specific pieces of silicon which are designed such that they excel at a limited set of tasks. Compared to general-purpose CPUs, these “XPUs” (using X here to denote the plethora of GPU, NPU, TPU, AIPU, and other PUs out there) can carry out a specific set of computational tasks highly efficiently. Some XPUs focus on energy efficiency, others on raw computational speed. However, they all share one property: for a specific set of operations they outperform existing CPUs by some efficiency metric.
We Need to Work Jointly to Grow the Edge AI Market
As of today, we are strongly concerned about the ease with which advances in software (novel algorithms) can be utilized on the newly emerging hardware (new accelerators). This in turn heavily influences the ease by which new edge AI applications can move beyond their first Proof of Concept (PoC) stage and truly become globally scaled products.1 Currently, the advances in software and hardware are not well aligned.
New silicon often requires very specific types of AI models, trained in particular ways. Thus, benefitting from hardware advances requires AI application developers to re-engineer their software and incorporate the software provided by the silicon manufacturer. The software provided by silicon manufacturers, far too often, is in its infancy. Software is an afterthought for those companies who specialize in new silicon manufacturing. As a result, the current XPU software is often hard to use, (partly) proprietary, or not yet ready for scaling up.
On the other hand, as a silicon creator, tapping into the vast ecosystem of edge AI application developers is hard: you have to provide software for AI application developers to use your hardware, but where do you start? The software ecosystem is moving so rapidly that all silicon vendors end up building their own, hard-to-use, partly proprietary, software.
The challenges faced by both edge AI application developers and silicon manufacturers to reap the benefits of our about-to-explode market need to be overcome for us to jointly benefit from the market potential in front of us. If we don’t provide an easy-to-use way for new software advances to be used on new hardware – and critically to be integrated into the much larger ecosystem of software, hardware, ISVs, licensing, support, etc. needed to bring a solution to the market – we will all lose.
The risk of not getting our act together as a field was recently worded nicely by an industry expert: “The way we are currently going, developers are tied into one ecosystem, and they cannot move to cheaper hardware – even though such hardware is available. As a community, we are at risk of creating the ‘$3000,- microwave’. The AI models in the microwave are great and provide value, but the cost of the hardware forces a price point that will never work.”
1Admittedly, many other challenging aspects come with scaling a solution; in this whitepaper, however, we solely focus on the issue of adopting new XPUs.
Standardization to Ensure Adoption and Fast Growth
In this whitepaper, we propose the Open AI Accelerator Exchange (OAAX). We will first describe how AI pipelines (i.e., the process of going from sensor data to meaningful application) are implemented, and what it means to accelerate parts of that pipeline. Next, we introduce our proposed open exchange to make acceleration easy. Finally, we will discuss the commitments of Network Optix to this open exchange: having benefited in the last 10 years from standards in the video industry (such as ONVIF), and having scaled video applications to millions of channels globally, we are committed to contributing to OAAX to enable the Vision+AI market to grow.
Accelerating AI Pipelines
What does it mean to use an XPU – an accelerator – to improve an AI pipeline? Without much loss of generality, let’s focus on Vision+AI applications for simplicity.
Explaining the VISION + AI pipeline
A pipeline in our jargon is the full process from the sensor – the camera – to the high-level application, for example, a bartender receiving a prompt on his phone that Table 2 needs to be attended to. The AI pipeline consists of several operations;2 operations are simply processes that take one specific form of data as input, and transform this data into a more meaningful format.3
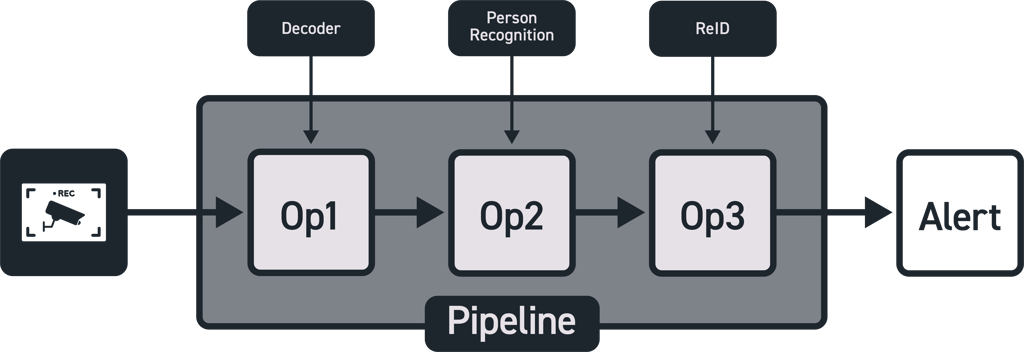
Fig 1. Abstract representation of a Vision+AI pipeline.
Following up on the bartender example briefly described in the introduction, consider the following pipeline (see Fig.1) and its four operations:
- A camera monitors 4 tables in the cafe; the camera produces an RTSP stream which is sent to an edge device implementing the application.
- Operation 1: The RTSP stream is decoded into individual 640x480 RGB image tensors, at a rate of 7 frames a second.
- Operation 2: An AI model (M1) takes as input the individual image tensors, and produces a list of coordinates of bounding boxes indicating the locations of people in the image.
- Operation 3: The content of each bounding box is fed as input to a second AI model (M2) which generates a unique ID for each person (e.g., ReID).
- Operation 4: The set of unique IDs, their location, and their timestamps is processed by a higher level rule-set to raise an alarm whenever a table is occupied, but has not been visited by any of the cafe staff for a set period of time.
In the above example, each of the four operations, decoding, M1, M2, and the rule-based algorithm described in the last step, could potentially benefit from implementation on an XPU.
2The term operations is very generic and could refer to bitwise operations such as AND or OR, or it could refer to large, black-box, functions (or AI models). At this point in the text the generic nature is deliberate: we will further specify our usage of the term as we go.
3The pipeline can abstractly be considered the process that governs which data is “fed” to which process and at which pace.
CPUs & XPUs Implementing an AI pipeline
Most XPUs on the market today facilitate speeding up one, or multiple, of the operations described above. Although the overall pipeline is governed by a process that runs on the CPU, specific operations are “outsourced” to the XPU.
In theory, the process of outsourcing operations to the XPU is easy: just figure out which operations benefit from the XPU's strengths, and move those operations4 to that chip (see Fig. 2). As long as operations are clearly defined, and the movement of data “inside” the pipeline – and hence between CPU and XPU is efficient – one can theoretically select any XPU to reap its benefits without having to go through significant re-engineering of the pipeline and the operations therein.
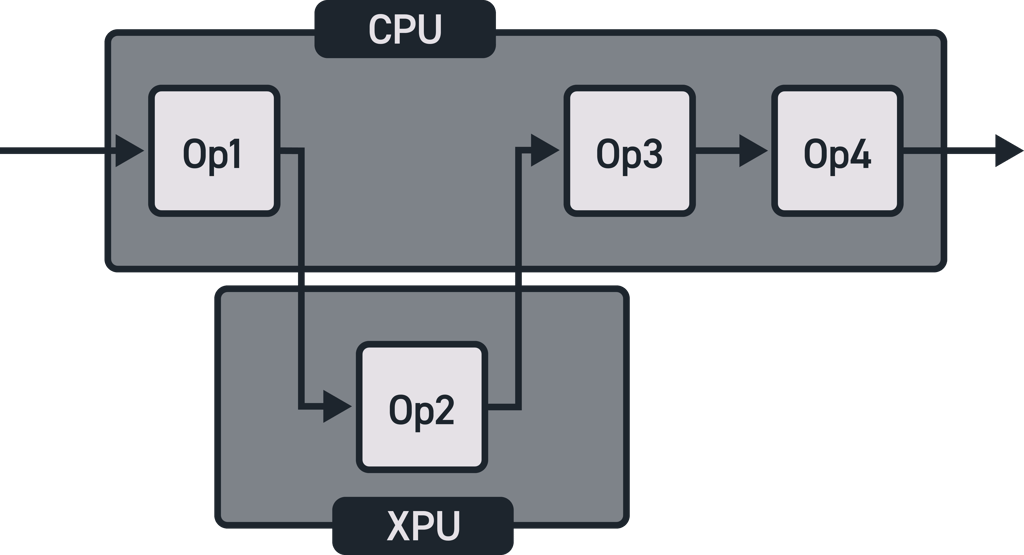
Fig 2. Schematic representation of “moving” a single operation – which can be a full DNN – to the XPU.
4 Note that here a set of operations is easily chained into a single, more elaborate operation. if operation 1 transforms data from X to Y, while operation 2 transforms data from Y to Z, we could just as well “chain” operations 1 and 2 to create operation 3 which transforms data from X to Z.
The Challenges When “Outsourcing” Operations
In practice, however, moving operations to an XPU is often challenging. AI application developers will need to know exactly which operations are supported by the selected XPU and, often, the operations need to be reimplemented such that they can be executed on the XPU. Second, the data “flowing” between the CPU and the XPU needs to be selected wisely: outsourcing super small operations (i.e., bitwise AND and ORs) to the XPU will incur high (memory) costs of moving data about, while outsourcing excessively large operations runs the risk of having to rebuild the full pipeline using XPU instructions.
Currently, we are stuck with a software ecosystem that works well on CPUs, and a proprietary ecosystem for specific GPUs. Moving selected operations in a pipeline over to newly added XPUs is a challenge that slows down the adoption of these novel bits of silicon: this hinders the market expansion of silicon makers. Additionally, the challenges in adopting new XPUs deprive application developers of the unique features of the new silicon (and this leads us to the ‘$3000 - microwave’).
Specifying Operations: Choosing the Right Level of Abstraction.
Before we dig into the specification of the Open AI Accelerator Exchange (OAAX) to address the above “XPU portability” problem, we want to briefly touch upon our use of the term operations. Effectively, we defined an operation simply as a function (mapping) of one type of data to the other. This is extremely general, but in such generality also very hard to work with: at this level of abstraction even tiny, bit-level, AND and ORs are considered operations. On the other hand, the full pipeline described above can also be considered a single operation.
For a generic operation specification to be useful, we have to choose the right level of abstraction. In our proposed exchange we focus on each AI model being a single operation5 that is potentially outsourced to the XPU.
5 Note that this notion of operation is different from the use of operations in the Open Neural Network Exchange standard (ONNX, see https://onnx.ai). The ONNX standard, which we suggest adopting as a starting point for OAAX, serves a different purpose and thus benefits from a different level of abstraction.
The OAAX Specification
In this section, we provide a first sketch of the specification of OAAX. We focus on accelerating individual AI models (i.e., M1 and M2 above). The specification sketch is knowingly and deliberately missing several details: this whitepaper is intended to rally a community around OAAX and the final specification of the standard should be a community effort.
High-Level Overview
Based on our experience supporting edge AI pipelines on a large variety of CPU/XPU combinations, the OAAX specification should consist of two parts:
- The first part of the specification is a standardized mechanism to transform (compile, cross-compile, reword, whatever name you want to give it) a generic, target-independent description of an operation into an XPU-dependent specification. We coin this first step the Operation Conversion Toolchain.
- The second part of the specification consists of a standardized method to run the target-specific specification of the operation inside the larger pipeline. I.e., this step consists of a mechanism to – for the process running on the CPU – “load” the specification and “run” it given specific input data. We call this second step the XPU Operation Runtime.
Jointly, the Operation Conversion Toolchain and the XPU Operation Runtime make up the OAAX specification.
The exchange is intended such that whenever a silicon manufacturer provides both parts of the standard to the public, it becomes instantly possible to deploy any number of supported operations to the XPU. From a silicon vendor perspective, this means that by committing to OAAX, AI application developers are instantly able to utilize your XPU. From a developer perspective, OAAX ensures that any CPU/XPU combination can, during the deployment stage, be targeted without any re-engineering.
In our first implementation of OAAX, we will recommend the use of ONNX – the Open Neural Network Exchange format as found on https://onnx.ai/ – as a starting point to specify an operation (i.e., we consider a full ONNX graph an operation). The OAAX does not fundamentally rely on ONNX, but we need a generic starting point to provide the sought-after portability: at this point ONNX seems the most universally accepted standard for such a generic specification of an operation.
Operation Conversion Toolchains
Abstractly, operation conversion toolchains are functions that take as input a generic description of an operation and generate as output a specific description of that same operation which can be executed on the targeted XPU. For such a conversion to be generically useful we need to have
a) a well-supported generic operation description, and
b) a well-supported ecosystem to implement and distribute the conversion toolchain function(s).To solve the first issue, we suggest adopting ONNX as a method of specifying – generically and in a device-independent fashion – the operations that need to be outsourced to the XPU. To solve the second problem, we suggest adopting Docker containers. Docker containers can be used to easily execute a single process from the command line on virtually any machine, and containers are extremely easily distributed.
Implementation Details
An operation conversion toolchain is a Docker container that can contain any code (it’s a black box for the user) that can be run using:
docker run -i --rm boot python convert.py < /path/to/model-file.onnx
The docker container can contain pretty much any code the silicon manufacturer would like to use to implement the XPU-specific conversion process from generic ONNX to XPU-specific output.
We suggest that the container by default generates a triplet consisting of:
- operations-file.ai. A file containing the operations specified in a format such that it can be executed – using the runtime, see below – on the XPU. The file should have a matching MIME type for the runtime.
- vignet.json. A json object containing any comments regarding the (successful) conversion process. The vignet contains a structured description of the runtime(s) suitable to run the operations-file.ai file and any conversion notes the user should be aware of.6
-
errors.json. A json object containing any errors. This should only be generated if the operations-file.ai is not generated. The errors.json file should contain specific information detailing why the conversion process failed (for example, the ONNX graph contains the relatively recent ONNX-operator GridSample for which there is no support on the XPU).
6 We often see that data types need to be adjusted to suit a specific XPU; for example, INT32’s are cast to INT8 or INT16. Such optimizations need to be communicated to the user in the vignette.
XPU Operation Runtime
The XPU operation runtime is simply a process that allows for the process running on the CPU to do two things:
- “Load” the XPU-specific operation specification “onto” the XPU, and
- “Run” the operation on provided input data.
Abstractly, if the operation runtime implements the above two functions, it can easily be integrated into a larger AI pipeline and used to execute the operation. When moving the pipeline over to a different CPU/XPU combination, one simply executes the target XPU’s conversion toolchain and subsequently ‘swaps’ the XPU-specific runtime within the pipeline; no other changes are needed.
Implementation details
For the first specification of the runtime, we suggest providing runtimes in the form of a compiled library (which can be easily integrated in a larger C/C++ pipeline) which provides an ABI disclosing the load and run operations.
For generic I/O to the library, we suggest using binary tensors submitted via msgpack;7 in our experience, this is both very generic (and thus can be used for a variety of input and output data types) and highly performant.8
8 We currently have several experimental implementations of XPU runtimes for a variety of XPUs which we use in Nx Vision+AI applications. With our support of OAAX, we will document our current implementations and make them public.
The ONNX Runtime
Although this white paper merely describes the high-level outlines of OAAX, it is meaningful to briefly reflect on the relationship between OAAX and the ONNX runtime. The ONNX runtime, when stripped down to its core, is simply a specific case of our suggested XPU Operation Runtime. This is easy to see when looking at Python code to load and run an ONNX model in the ONNX Runtime:
# Load the operation:
session = onnxruntime.InferenceSession('resnet50v2/resnet50v2.onnx', None)
# Run the Operation:
output = session.run([data])
So, using an ONNX file for AI model deployment and inference using the ONNX runtime is simply an implementation of OAAX:
- The Toolchain simply maps ONNX to ONNX.
- The Runtime loads operations-file.onnx and allows it to be executed.
In the OAAX, we generalize this implementation to provide more flexibility for resource-constrained XPU/CPU combinations: due to the black-box nature of the toolchains in OAAX, a toolchain could produce ONNX, but it could also produce (e.g.,) a binary description of a combination of multiple XPU specific operations. This generality ensures that XPUs can be added while maintaining native performance.9
9Due to its “interpretive” nature the ONNX runtime is by default relatively large (it contains implementations for all ONNX operators), and relatively slow (or it needs on-device compilation). Thus, while suitable for some applications, we have designed OAAX as a superset to the ONNX / ONNX Runtime implementation.
Opening Up the Accelerator
We have by now motivated why we think the Open AI Accelerator Exchange is highly needed: it opens up our market and makes using the right hardware easier. We have also outlined the main components of the exchange: at this moment in time, we are actively developing a standard and inviting XPU manufacturers and AI application builders alike to help in its further specification and implementation. However, it is good to properly understand the power of OAAX.
Obviously, OAAX can be used by individual developers. If a developer wants to move a piece of an AI pipeline, generically specified in ONNX, to a specific XPU, they need only download the supplied OAAX toolchain docker container and run it locally to convert the operation. Next, the simple inclusion of the runtime into the pipeline ensures that the XPU has been integrated. Thus, making conversion toolchains and runtimes openly available makes porting to a new XPU extremely easy to do, while the OAAX provides XPU manufacturers with all the flexibility they need to guarantee native performance.
However, the exchange truly comes to life when embedded in a larger ecosystem. This is exactly what we have done at Network Optix (Nx, more on us later). Fig 3. provides a schematic overview of how we use OAAX to create fully portable – device-agnostic – AI pipelines:
- We specify a generic pipeline. For Vision+AI pipelines Nx openly provides all the tools to easily capture video streams, decode them, resize them, etc. Also, Nx provides the tools to easily augment streams with metadata (for example AI object detections) and visualize these for a large number of concurrent streams).
- After the pipeline has generically been specified, the AI models therein – the operations that potentially benefit from acceleration – can automatically be passed through all available toolchains, thus, in the Nx Cloud, we make sure that the same model is available for a plethora of XPUs.
- When installing Nx server on an edge device, and enabling the Nx AI manager on that device, we will automatically install the runtime that is fitting for the device. Thus, if the device contains a specific XPU, we will install the runtime that has been contributed for that XPU.
- From the Nx cloud, we can subsequently, automatically, deploy the version of the operation that exploits the target XPU.
The above setup allows one to effectively “swap” an edge device and automatically benefit from its CPU/XPU combination.
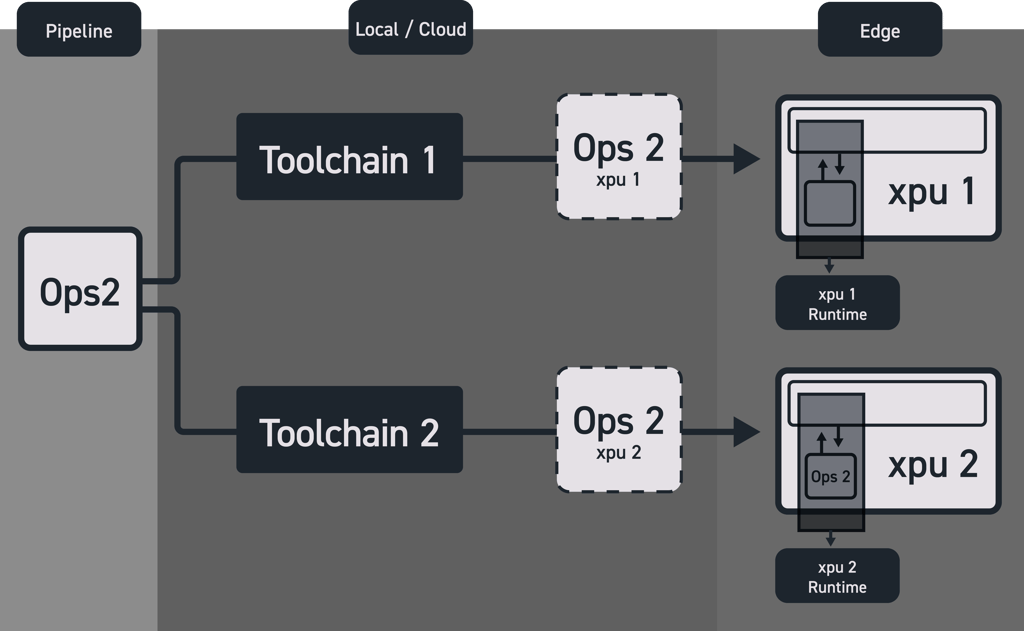
Fig 3. Overview of the process of mass deployment to a diverse fleet of edge devices using the OAAX(as implemented in the Nx AI Manager & Nx Cloud).
The Nx Commitment
This whitepaper is intended to rally together a community to create and support the OAAX specification; we hope to have motivated the benefits for our whole community. Currently, within the Nx AI Manager, we have already implemented the first version of the OAAX standard and can support pipeline acceleration for several specific targets (Intel, ARM, Qualcomm, NXP, Hailo, Rockchip, and AMD).
To support OAAX, Network Optix is committed to the following:
- Specification: We will actively contribute to specifying OAAX; we are starting today by circulating this whitepaper. Shortly, we will provide documentation and reference implementations on Github (https://github.com/OAAX-standard/OAAX).
- Contribution: As noted, we have a first, experimental, implementation of OAXS available within the Nx AI Manager / Nx Cloud. We will make our implementations of the toolchain and runtimes available to the community.
- Adoption: We will integrate OAAX into the Nx Developer Tools (Nx Meta). This means that any XPU supporting OAAX is immediately supported within the Nx ecosystem. The Nx AI manager will ensure runtime optimization (as detailed in Fig 3.), and the larger Nx stack will enable developers to build production-ready Vision+AI solutions in minutes.
Join us in our commitment. Looking to contribute to, or benefit from, OAAX? Learn more at https://oaax.org
About Network Optix
Network Optix is a software development company specializing in video management solutions. Founded in 2010, the company focuses on creating innovative and user-friendly software to manage and analyze video data efficiently. Our flagship product, Nx Witness, is a comprehensive video management platform designed to meet the needs of various industries, including security, retail, transportation, and more. Nx Witness offers features such as advanced video analytics, multi-site management, and compatibility with a wide range of cameras and devices.
Network Optix is committed to delivering cutting-edge solutions to empower organizations to harness the full potential of video technology for security and operational insights.
The Nx Server, Network Optix’s edge software to manage camera streams, currently powers over 5 million camera channels globally. Nx Client, Cloud, and Mobile, easily adapted interfaces to any Nx-supported camera, currently power dozens of Vision and Vision+AI applications.
About the Author
Prof. Dr. Maurits Kaptein, a full professor of statistics at the Technical University of Eindhoven, the Netherlands, also serves as the Chief Data Scientist at Network Optix Inc., based in California. With over two decades of experience, he has pioneered the practical application of machine learning and AI across diverse sectors such as e-commerce, healthcare, and computer vision. Notably, he played a pivotal role in popularizing the multi-armed bandit (MAB) approach for online content optimization, developing innovative and scalable solutions for web-based MAB problems. He co-founded Scailable BV, which was dedicated to hardware-agnostic edge AI deployment, and led the company until its acquisition by Network Optix in early 2024. He now spearheads the creation of an open ecosystem at Network Optix, aimed at democratizing vision-based edge AI solutions. Maurits has authored or co-authored four books and over 100 papers in prestigious academic journals.