

6 minute read
Two weeks ago, during the Embedded Vision Summit, I was lucky enough to give a presentation about the vision of Network Optix and how we provide the tools needed to scale a vision AI application from proof of concept to global product.
As a part of the talk, I discussed the Open AI Accelerator eXchange (OAAX), a recent effort to open source our in-house developed technology to make edge AI model deployment across various hardware platforms as easy as possible. After the presentation, we received several questions regarding OAAX, its use, and its relation to other projects in the space. In this blog post, I will answer these questions. However, if you have any remaining questions please start a discussion in the OAAX GitHub.
A Brief Recap of OAAX and Its Aims.
Before digging into the questions posed during the summit, let me provide a brief recap of OAAX and its aims. For a full write-up, see our position paper on GitHub.
We began working on OAAX as we moved trained AI/ML models, stored in ONNX format, to various edge devices. Naturally, we moved between ARM, Intel, and Qualcomm silicon. However, on the edge, we also wanted to benefit – depending on the use case – from the rapid advances in AI-specific accelerators. We wanted to reap the benefits of the GPUs, NPUs, and FPUs (let’s call them XPUs for now) provided by NVIDIA, Hailo, Axelera, MemryX, NXP, and many others. We developed the in-house capability to make moving from one target to another as easy as possible, and we are now open-sourcing the core of that effort (see the Github repositories).
Developing this capability, we focused solely on model inference (not on the surrounding pipeline, see Figure 1). We simply tried to make the process of generating inferences from a trained AI model M, given input data d as easy as possible (i.e., we want to compute M(d)). Usually, this requires a runtime R which can load M and compute R(M(d)).
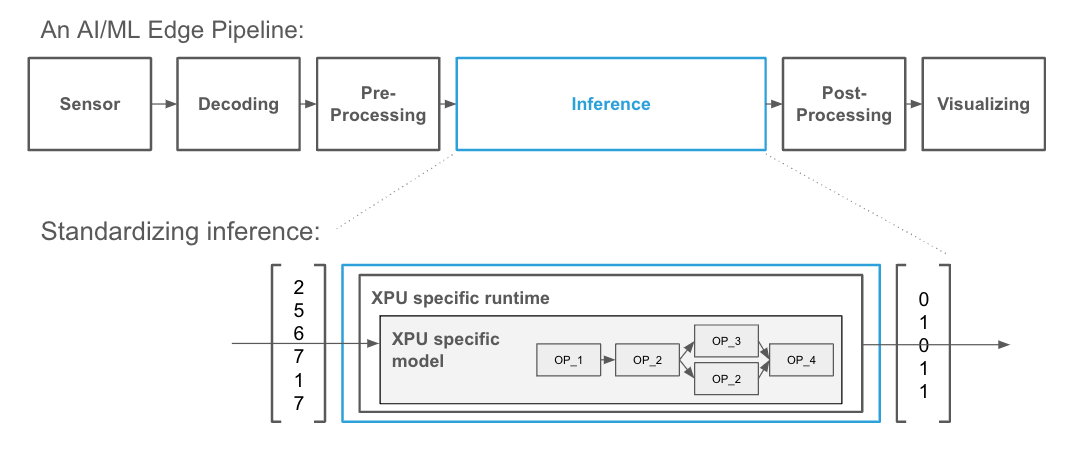
Fig. 1: OAAX focuses solely on standardizing the inference process.
For each specific target, the process of generating inference from a trained model on that hardware often required digging through the manufacturer's software documentation, finding specific API/ABI calls, learning about the specific operations the chip supports, and implementing the interactions with the manufacturer provided runtime R such that inferences could be computed. This process was often cumbersome and could take a lot of time. However, “zooming out”, the process for virtually any accelerator was always the same (see Figure 2):
- Given a (generic) model M, convert it to a model specification that can be executed on the target hardware (i.e., construct M’)
- Given the application software, integrate the hardware vendor supplied runtime R’ which can run model M’ such that M’(d) can be computed using R’ (i.e, execute R’(M’(d))).


Fig. 2: a) the “black box” conversion process from model M in ONNX format to model M’ which can be executed by the target-specific runtime R’. b) Schematic representation of target specific runtime R’; as long as the interface is standardized, the runtime can effectively be exchanged.
Thus, OAAX, in its core, is nothing more than an abstraction layer that formalizes the processes of converting M to M’, and standardizes the interface of R’. This means that, although both the conversion process and the on-device runtime can remain a black box to the developer (providing the hardware manufacturers with a large freedom of implementation), the process of moving from one target to another simply becomes:
- Running the black box conversion process for the intended target locally (or in the cloud) to obtain the target specific model specification M’
- “Swapping” the runtime interface within the larger edge AI application code for the target specific runtime R’.
OAAX standardization ensures that R’M’(d) can be computed given the correct M’ and R’ combination. Figure 3 illustrates how OAAX allows moving between different targets effortlessly.
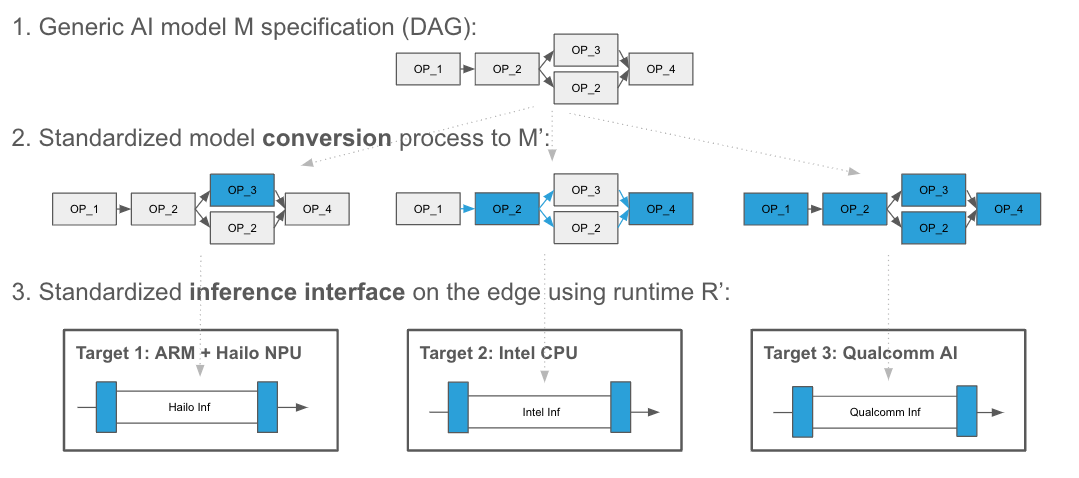
Fig. 3: The process of moving from one target accelerator to another as facilitated by OAAX: a standardized model conversion process, and a standardized runtime interface for inclusion into the host application. The conversion might convert specific operators or types, or group operators. The runtime could run on any combination of CPU and XPU, as long as the host-level interface is standardized.
The Questions
Now, let’s get to the questions asked during EVS. I will try to group them a bit according to the subject.
Current Accelerator Support
We received several questions after the EVS presentation regarding current target support. I.e., “What processors and accelerators are supported?”, “Besides ARM, Intel, and Nvidia, which other processors are supported or will be supported and when?”, and “What is the current status in terms of the support edge devices?”
The answers here are relatively simple: the currently publicly available conversion toolchains and runtimes are listed here: https://github.com/OAAX-standard/contributions.
Public support for Qualcomm, ARM32, OpenVino, and many others is expected in the coming weeks. If you are interested in adding your own, please see the reference implementations.
Keeping Up with the Field
Essential questions related to our commitment and how we intend to keep up with the rapidly advancing field of AI models and hardware. I.e., “How do you adapt to the fast-changing models, operations, and data formats and how to check if the hardware supports it?” and “How much buy-in do you have from the hardware vendors?”
To start, within Network Optix, and specifically in the Nx Toolkit, we actively work together with hardware vendors to provide support for their hardware. This means we have a team of people who integrate target-specific conversion processes into the Nx AI Manager and ensure appropriate runtimes are installed on the target devices. Hence, we have active collaborations with virtually all AI hardware providers. It is our commitment to ensure that as many implementations as we build can be opened up (where this decision is often in the hands of the hardware manufacturer). Thus, we collaborate with close to every vendor and are actively trying to persuade them to open up.
Thus, there is buy-in. That said, keeping up is hard; new ONNX operators (or versions thereof emerge), new advances in chips might require changes to the conversion process or runtime, etc. However, we are content that if we organize one single source for such changes to be adopted, one that we at least actively contribute to, it becomes easier for everyone in the field to find the most recent versions. Why would you need to consult every hardware vendor’s specific documentation to find out which of them supports the newest added ONNX operator? It is easier for both developers and hardware manufacturers if things come together in one place; With OAAX, we intend to organize that place.
OAAX Scope
We received many questions along this line: “Does OAAX address data pre-processing and post-processing that is required by many models?”
Nope. Although the actual cut-off might not always be as clear cut as one would expect (i.e., should quantization of the input tensor be regarded as pre-processing?), we aim to focus on “tensor-in, tensor out” model inference generation.
Comparing OAAX to Others
We also received a number of questions regarding the relation of OAAX to other efforts in the field. Let's tackle these one by one:
“How can OAAX be compared or complement other activities from Modular or tools from providers like Edge Impulse?”
Functionally there might be overlaps, and with OAAX we hope to provide an open structure into which other tools can be integrated. For example, within Nx, we routinely use tools provided by Edge Impulse to train models. Next, we export the model to ONNX and deploy the trained model to an edge device using the Nx AI Manager. Here, under the hood, we use OAAX for deployment of that model to an Nx server running on specific hardware.
“Is your toolchain built on MLIR or TVM or any other graph compiler? Or does the HW vendor provide their own compiler toolchain to you?” and “Is OAAX a compiler like TVM? Or will hardware manufacturers have to develop compilers on top of OAAX?
The OAAX toolchains are, in some way, one level of abstraction up from this question. OAAX toolchains are simply provided as Docker images which can be executed from the command line. Supply the input ONNX file (and potentially additional validation data), and the container creates the resulting model artifact. Creators of an OAAX toolchain can use whatever tools they would like in the black-box, as long as the resulting file can be executed by the matching target-specific runtime.
“There are existing standards like OPENVX and NNEF from Khronos which are meant for performance portable applications. Are you using these in your solution?”
In our view, most existing tools use different levels of abstraction than most of these tools, although there are obvious overlaps in potential use cases. With OAAX, we aim to standardize the process of moving from one target to another, given a trained model; many existing attempts can be facilitated by simply wrapping a standardized interface. We are currently not using OPENVX or NNEF specifically but would love to see user contributions to our git that include these initiatives.
Comparing to Pipelines
“How is this differentiated from Gstreamer and NNstreamer open project, that provides the pipeline capability?”
As stated above, OAAX does not aim to support the full pipeline. OAAX runtimes can be thought of as a single “block” in a larger pipeline; it would be great to ensure these blocks can easily be included in pipeline specification tools such as Gstreamer and NNstreamer.
What About the Larger ONNX Ecosystem
And finally, “Can you speak more to how ONNX fits in the framework?”
OAAX builds on ONNX in the sense that we adopt ONNX as the target-agnostic model specification M which can be converted into the target-specific model specification M’. Note that, in due time, having auxiliary toolchains that convert from different formats (TFLite, PyTorch) to ONNX within the OAAX ecosystem would be useful. We could simply adopt the OAAX Docker conversion toolchain specification to distribute such auxiliary conversion processes.
Although not directly included in the question, one could also wonder how ONNX + the ONNX Runtime relates to OAAX. The ONNX Runtime, with target-specific execution providers, allows for the execution of ONNX models on various targets. We see this combination simply as a special case of OAAX as shown in figure 4:
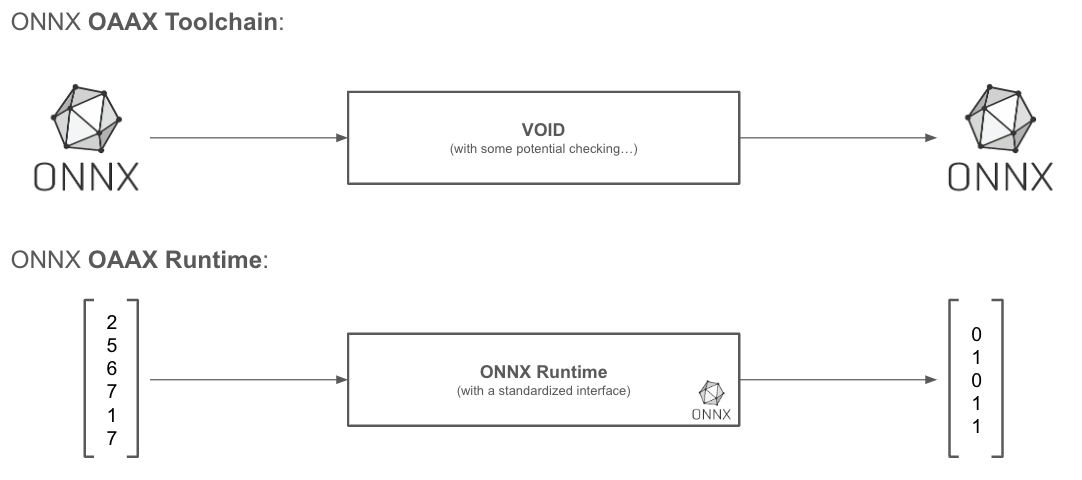
Fig. 4: Using ONNX models (both for M and M’) and using the ONNX runtime as a target specific runtime R’ is simply a special case of OAAX.
If you are looking to get actively involved in OAAX, either as a user, a contributor, or a member company, please check out the OAAX github and/or leave your email at oaax.org.